Snowflake vs Amazon Redshift vs Google BigQuery
a comparative analysis of cloud data management solutions for BI & Analytics.
Elastic Data Warehouse — is the modern solution for Data Analytics to address the desire to give direct access to reports & analytics; it requires flexibility and adaptability in both resources & data processing. Cloud is a key enabling technology for its ability to support an elastic infrastructure.
Elastic data warehouse is about scale. Although it is easy to focus on the volume of data, elastic data warehousing is primarily about adapting to any scale without added complexity or disruption.
As of Feb 2019, there are 3 main competitors in this space who can make the transition from the traditional star schema based data warehousing to a modern elastic data warehouse platform possible.
Below are notes from my evaluation of the 3 —


Sources for their individual adoption: Snowflake, RedShift, BigQuery
Snowflake receives the highest score cause of its product, support, and service among the other competing vendors (per Gartner & Dresner Advisory Services).


Snowflake brilliantly separates storage, compute and metadata management, trillions of rows can be sliced up with ease by concurrent users. Storage and compute can be scaled up and down independently and immediately, and the metadata service will automatically scale up and down as necessary.
Redshift does not separate Storage and Compute. If you need more Storage, you would need to add additional nodes, which means you are essentially paying for more compute power.




With Redshift, it is required to Vacuum/Analyze tables regularly. Snowflake manages all of this out of the box. With very big tables, this can be a huge headache with Redshift.

BigQuery bills per-query, so you only pay for exactly what you use.
Market Share:
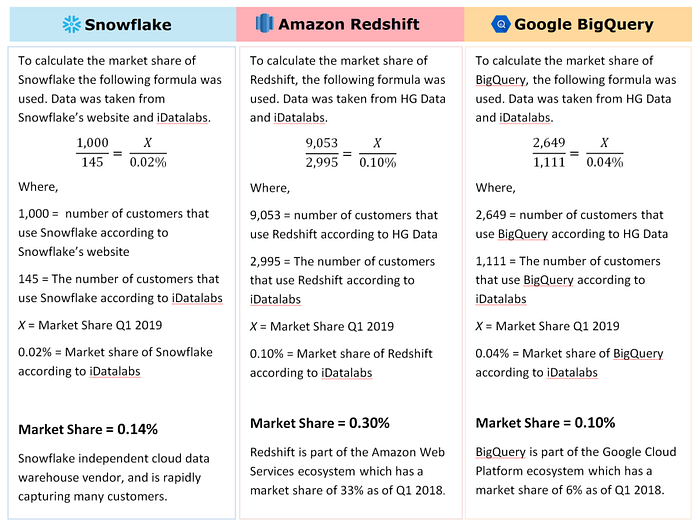

In summary, these warehouses all have excellent price and performance. These data warehouses undoubtedly use the standard performance tricks: columnar storage, cost-based query planning, pipelined execution, and just-in-time compilation. We should be skeptical of any benchmark claiming one data warehouse is orders-of-magnitude faster than another.
The most important differences between warehouses are the qualitative differences caused by their design choices: some warehouses emphasize tunability, others ease-of-use. If you’re evaluating data warehouses, you should demo multiple systems, and choose the one that strikes the right balance for you. For my team, Snowflake seems to be fitting our model.
Thanks for reading.
